Publications
2025
-
 DG16M: A Large-Scale Dataset for Dual-Arm Grasping with Force-Optimized GraspsMd Faizal Karim*, Mohammed Saad Hashmi*, Shreya Bollimuntha, Mahesh Reddy Tapeti, Gaurav Singh, Nagamanikandan Govindan, K Madhava KrishnaUnder Review, 2025
DG16M: A Large-Scale Dataset for Dual-Arm Grasping with Force-Optimized GraspsMd Faizal Karim*, Mohammed Saad Hashmi*, Shreya Bollimuntha, Mahesh Reddy Tapeti, Gaurav Singh, Nagamanikandan Govindan, K Madhava KrishnaUnder Review, 2025Dual-arm robotic grasping is crucial for handling large objects that require stable and coordinated manipulation. While single-arm grasping has been extensively studied, datasets tailored for dual-arm settings remain scarce. We introduce a large-scale dataset of 16 million dual-arm grasps, evaluated under improved force-closure constraints. Additionally, we develop a benchmark dataset containing 300 objects with approximately 30,000 grasps, evaluated in a physics simulation environment, providing a better grasp quality assessment for dual-arm grasp synthesis methods. Finally, we demonstrate the effectiveness of our dataset by training a Dual-Arm Grasp Classifier network that outperforms the state- of-the-art methods by 15%, achieving higher grasp success rates and improved generalization across objects.
-
 DA-VIL: Adaptive Dual-Arm Manipulation with Reinforcement Learning and Variable Impedance ControlMd Faizal Karim*, Shreya Bollimuntha*, Mohammed Saad Hashmi, Autrio Das, Gaurav Singh, Srinath Sridhar, Arun Kumar Singh, Nagamanikandan Govindan, K Madhava KrishnaICRA, 2025
DA-VIL: Adaptive Dual-Arm Manipulation with Reinforcement Learning and Variable Impedance ControlMd Faizal Karim*, Shreya Bollimuntha*, Mohammed Saad Hashmi, Autrio Das, Gaurav Singh, Srinath Sridhar, Arun Kumar Singh, Nagamanikandan Govindan, K Madhava KrishnaICRA, 2025Dual-arm manipulation is an area of growing interest in the robotics community. Enabling robots to perform tasks that require the coordinated use of two arms, is essential for complex manipulation tasks such as handling large objects, assembling components, and performing human-like interactions. However, achieving effective dual-arm manipulation is challenging due to the need for precise coordination, dynamic adaptability, and the ability to manage interaction forces between the arms and the objects being manipulated. We propose a novel pipeline that combines the advantages of policy learning based on environment feedback and gradient-based optimization to learn controller gains required for the control outputs. This allows the robotic system to dynamically modulate its impedance in response to task demands, ensuring stability and dexterity in dual-arm operations. We evaluate our pipeline on a trajectory-tracking task involving a variety of large, complex objects with different masses and geometries. The performance is then compared to three other established methods for controlling dual-arm robots, demonstrating superior results.


2024
-
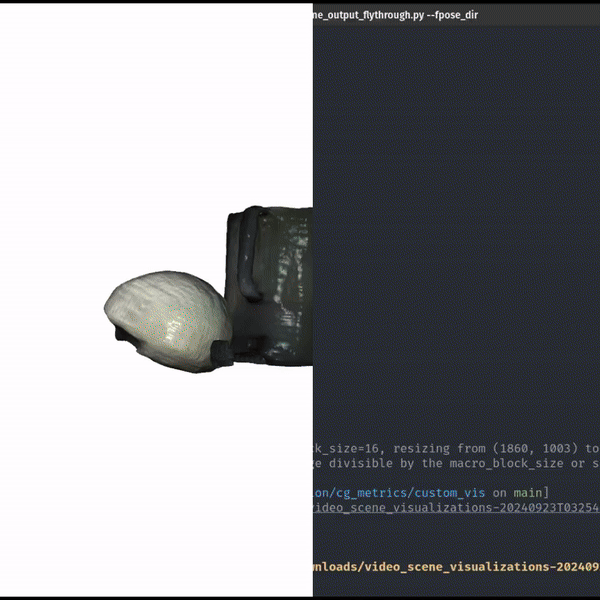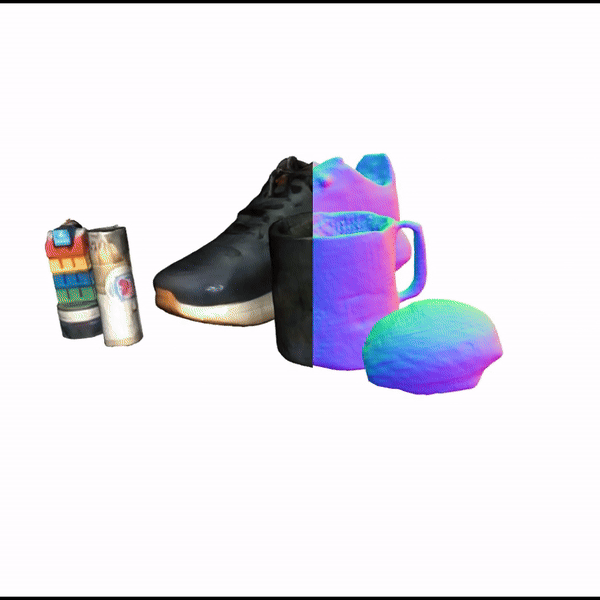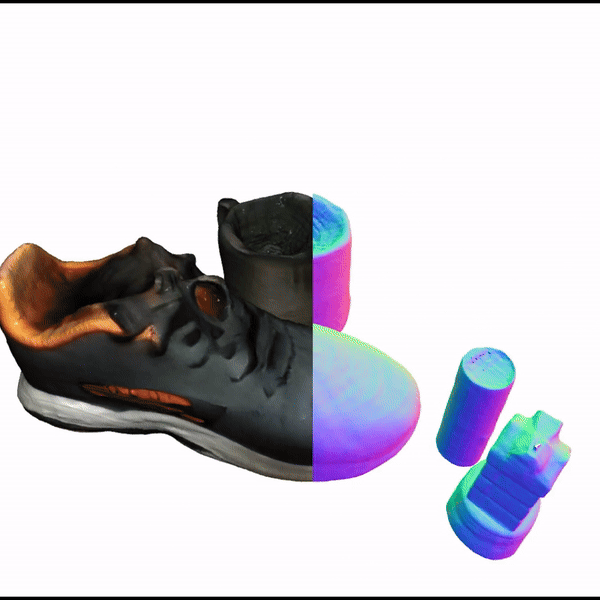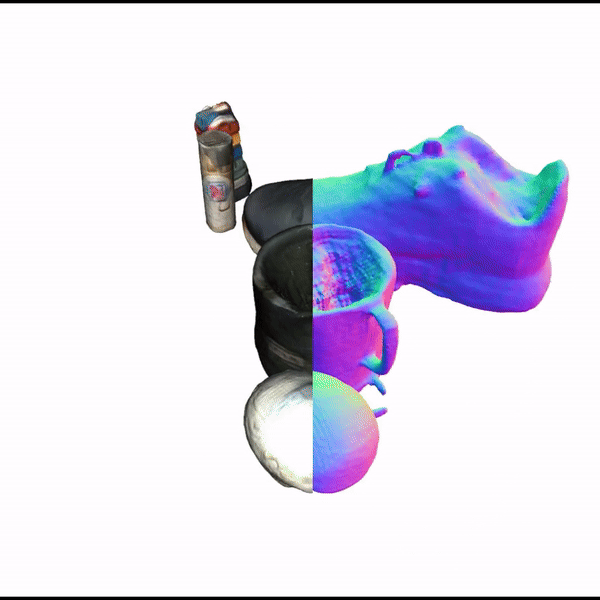 SceneComplete: Open-World 3D Scene Completion in Complex Real World Environments for Robot ManipulationAditya Agarwal, Gaurav Singh, Bipasha Sen, Tomás Lozano-Pérez, Leslie Pack KaelblingArxiv, 2024
SceneComplete: Open-World 3D Scene Completion in Complex Real World Environments for Robot ManipulationAditya Agarwal, Gaurav Singh, Bipasha Sen, Tomás Lozano-Pérez, Leslie Pack KaelblingArxiv, 2024Careful robot manipulation in every-day cluttered environments requires an accurate understanding of the 3D scene, in order to grasp and place objects stably and reliably and to avoid mistakenly colliding with other objects. In general, we must construct such a 3D interpretation of a complex scene based on limited input, such as a single RGB-D image. We describe SceneComplete, a system for constructing a complete, segmented, 3D model of a scene from a single view. It provides a novel pipeline for composing general-purpose pretrained perception modules (vision-language, segmentation, image-inpainting, image-to-3D, and pose-estimation) to obtain high-accuracy results. We demonstrate its accuracy and effectiveness with respect to ground-truth models in a large benchmark dataset and show that its accurate whole-object reconstruction enables robust grasp proposal generation, including for a dexterous hand.
-
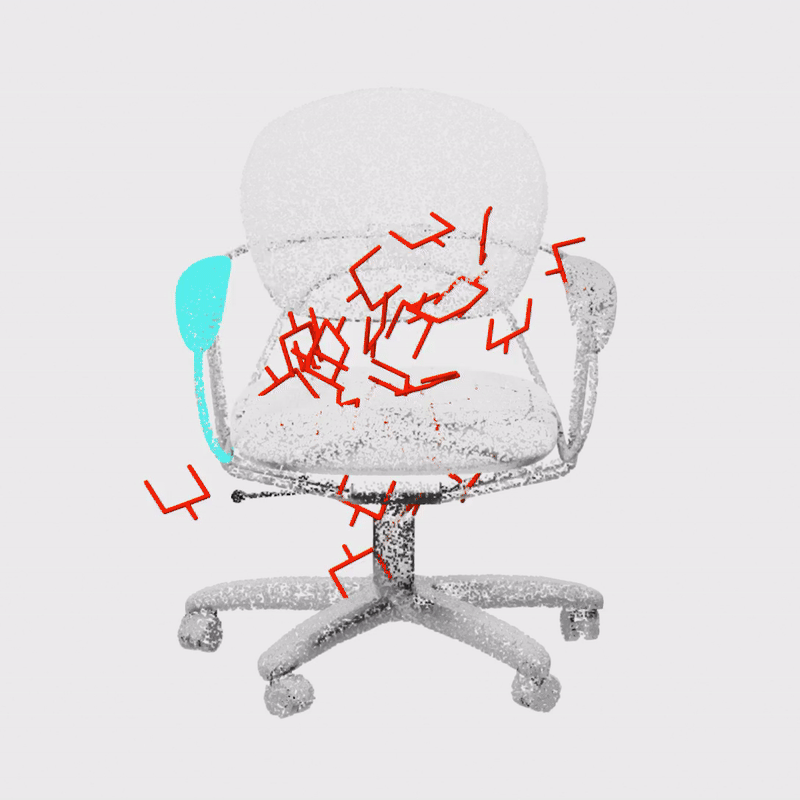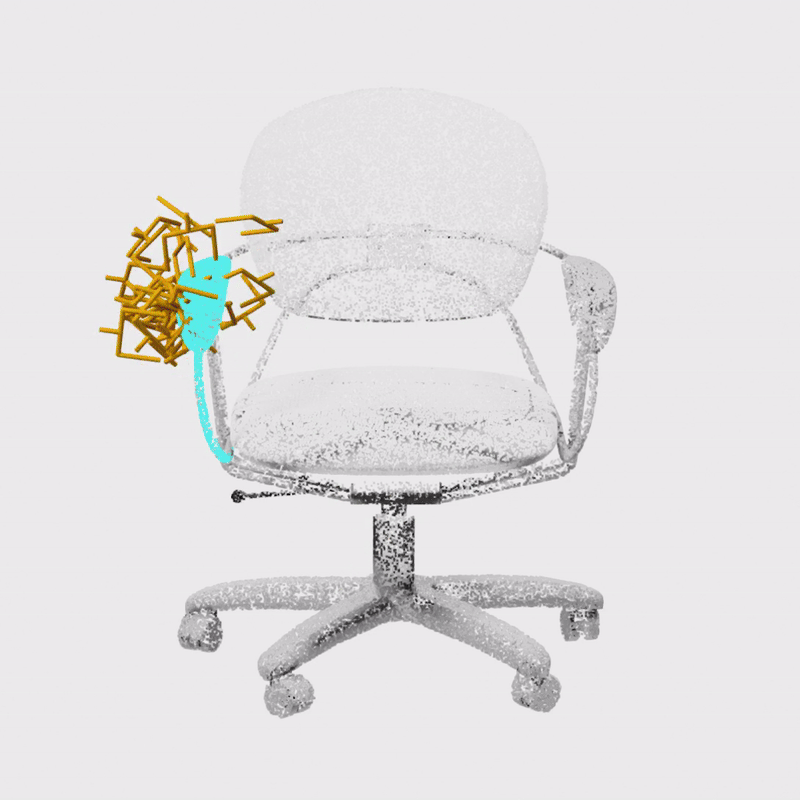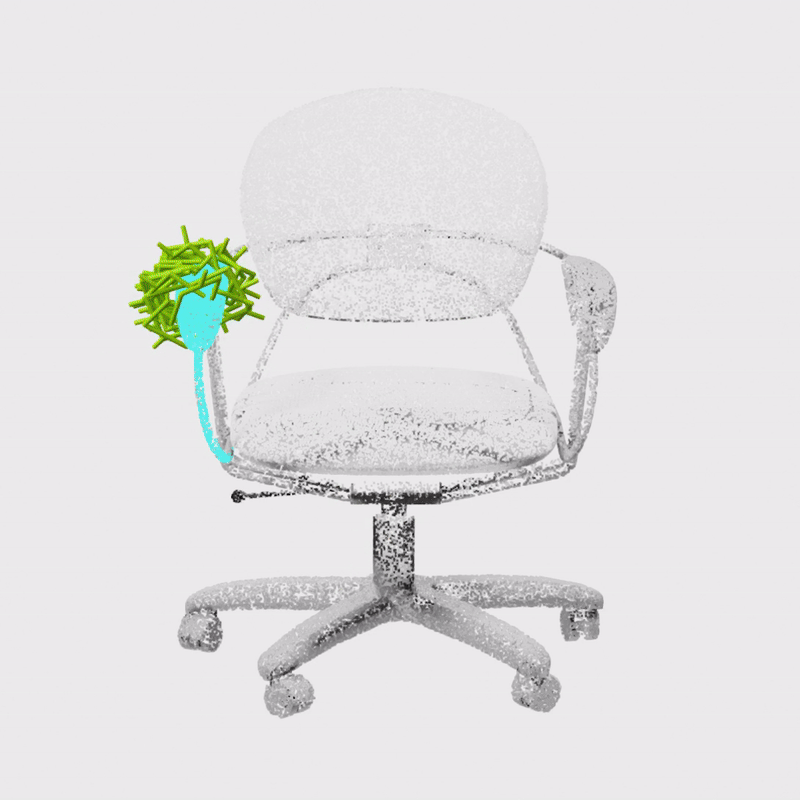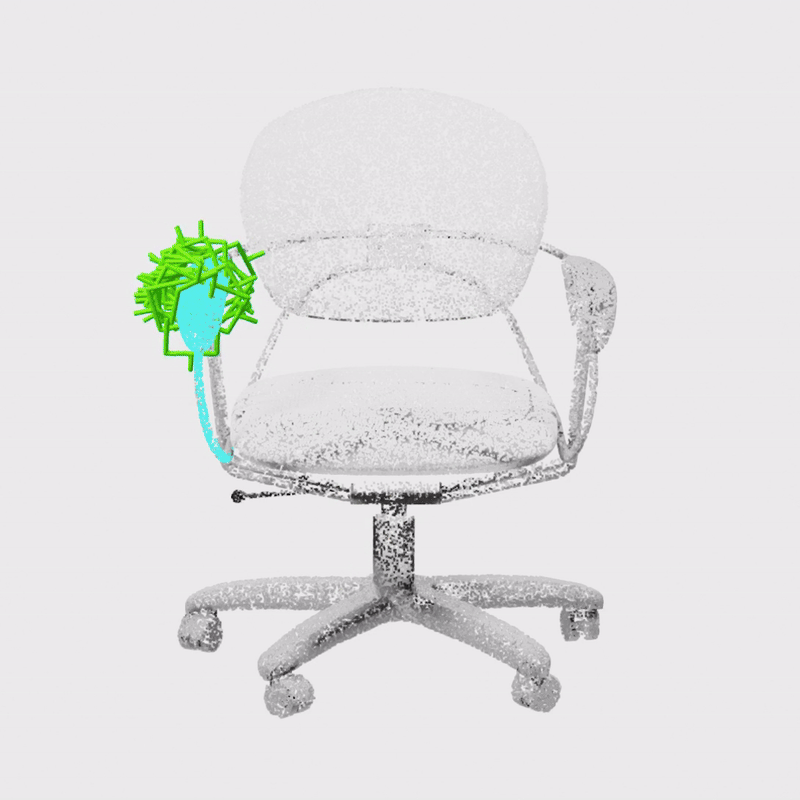 Constrained 6-DoF Grasp Generation on Complex Shapes for Improved Dual-Arm ManipulationGaurav Singh*, Sanket Kalwar*, Md Faizal Karim, Bipasha Sen, Nagamanikandan Govindan, Srinath Sridhar, K. Madhava KrishnaIROS, 2024
Constrained 6-DoF Grasp Generation on Complex Shapes for Improved Dual-Arm ManipulationGaurav Singh*, Sanket Kalwar*, Md Faizal Karim, Bipasha Sen, Nagamanikandan Govindan, Srinath Sridhar, K. Madhava KrishnaIROS, 2024Efficiently generating grasp poses tailored to specific regions of an object is vital for various robotic manipulation tasks, especially in a dual-arm setup. This scenario presents a significant challenge due to the complex geometries involved, requiring a deep understanding of the local geometry to generate grasps efficiently on the specified constrained regions. Existing methods only explore settings involving table-top/small objects and require augmented datasets to train, limiting their performance on complex objects. We propose CGDF: Constrained Grasp Diffusion Fields, a diffusion-based grasp generative model that generalizes to objects with arbitrary geometries, as well as generates dense grasps on the target regions. CGDF uses a part-guided diffusion approach that enables it to get high sample efficiency in constrained grasping without explicitly training on massive constraint-augmented datasets. We provide qualitative and quantitative comparisons using analytical metrics and in simulation, in both unconstrained and constrained settings to show that our method can generalize to generate stable grasps on complex objects, especially useful for dual-arm manipulation settings, while existing methods struggle to do so.


2023
-
 HyP-NeRF: Learning Improved NeRF Priors using a HyperNetworkBipsaha Sen*, Gaurav Singh*, Aditya Agarwal*, Rohith Agaram, K. Madhava Krishna, Srinath SridharNeurIPS, 2023
HyP-NeRF: Learning Improved NeRF Priors using a HyperNetworkBipsaha Sen*, Gaurav Singh*, Aditya Agarwal*, Rohith Agaram, K. Madhava Krishna, Srinath SridharNeurIPS, 2023Neural Radiance Fields (NeRF) have become an increasingly popular representation to capture high-quality appearance and shape of scenes and objects. However, learning generalizable NeRF priors over categories of scenes or objects has been challenging due to the high dimensionality of network weight space. To address the limitations of existing work on generalization, multi-view consistency and to improve quality, we propose HyP-NeRF, a latent conditioning method for learning generalizable category-level NeRF priors using hypernetworks. Rather than using hypernetworks to estimate only the weights of a NeRF, we estimate both the weights and the multi-resolution hash encodings resulting in significant quality gains. To improve quality even further, we incorporate a denoise and finetune strategy that denoises images rendered from NeRFs estimated by the hypernetwork and finetunes it while retaining multiview consistency. These improvements enable us to use HyP-NeRF as a generalizable prior for multiple downstream tasks including NeRF reconstruction from single-view or cluttered scenes and text-to-NeRF. We provide qualitative comparisons and evaluate HyP-NeRF on three tasks: generalization, compression, and retrieval, demonstrating our state-of-the-art results.
-
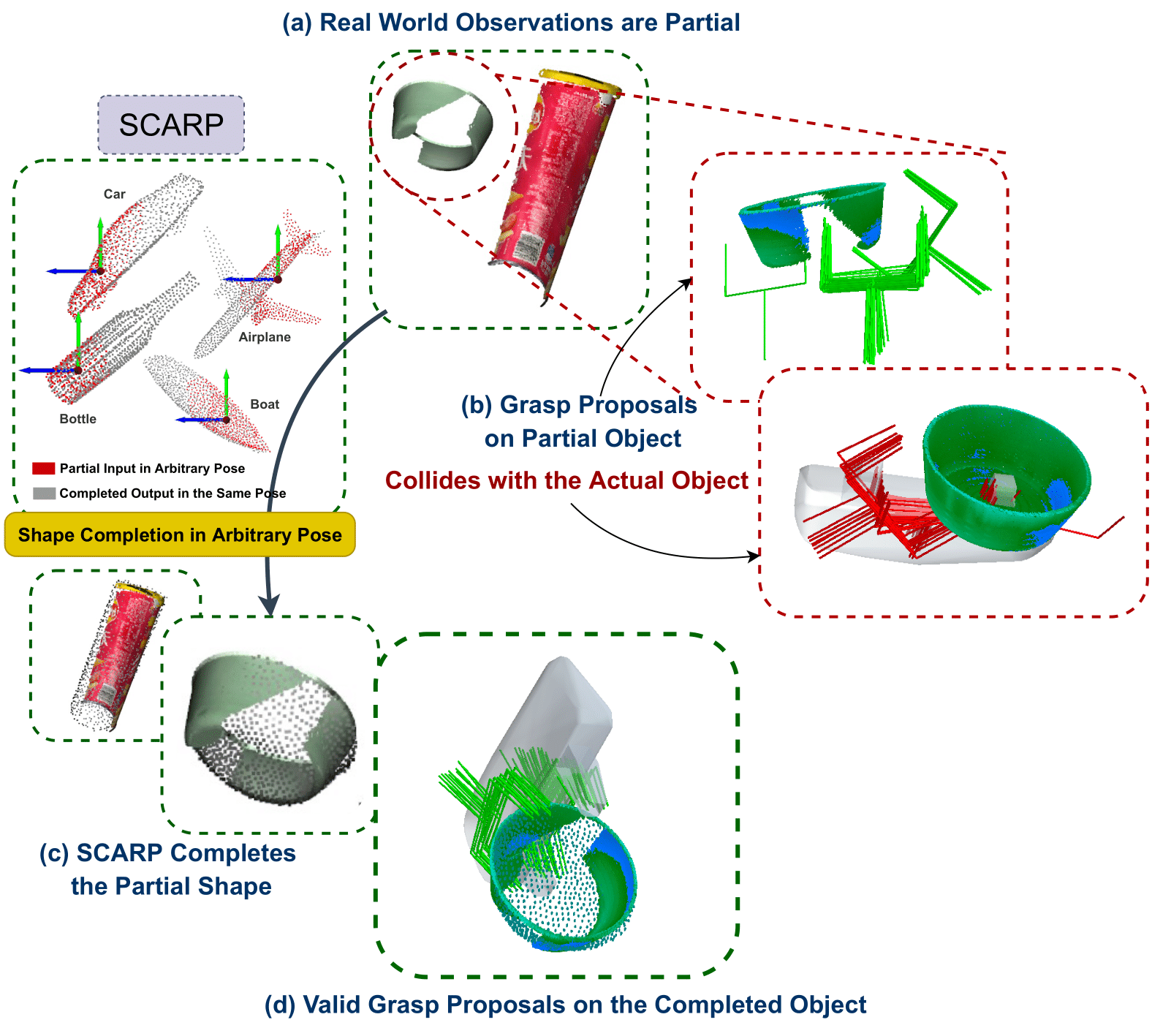 SCARP: 3D Shape Completion in ARbitrary Poses for Improved GraspingBipsaha Sen*, Aditya Agarwal*, Gaurav Singh*, B. Brojeshwar, Srinath Sridhar, K. Madhava KrishnaIn 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023
SCARP: 3D Shape Completion in ARbitrary Poses for Improved GraspingBipsaha Sen*, Aditya Agarwal*, Gaurav Singh*, B. Brojeshwar, Srinath Sridhar, K. Madhava KrishnaIn 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023Recovering full 3D shapes from partial observations is a challenging task that has been extensively addressed in the computer vision community. Many deep learning methods tackle this problem by training 3D shape generation networks to learn a prior over the full 3D shapes. In this training regime, the methods expect the inputs to be in a fixed canonical form, without which they fail to learn a valid prior over the 3D shapes. We propose SCARP, a model that performs Shape C ompletion in ARbitrary Poses. Given a partial pointcloud of an object, SCARP learns a disentangled feature representation of pose and shape by relying on rotationally equivariant pose features and geometric shape features trained using a multi-tasking objective. Unlike existing methods that depend on an external canonicalization method, SCARP performs canonicalization, pose estimation, and shape completion in a single network, improving the performance by 45% over the existing baselines. In this work, we use SCARP for improving grasp proposals on tabletop objects. By completing partial tabletop objects directly in their observed poses, SCARP enables a SOTA grasp proposal network improve their proposals by 71.2% on partial shapes.

